Как запустить локально LLM, если ее веса не помещаются в [видео]память
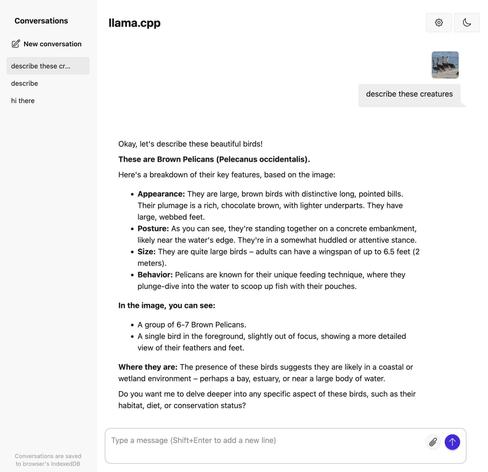
Некоторые люди предпочитают пользоваться не только облачными сервисами, но и запускать LLM у себя дома. Например, так можно запустить дообученные модели без цензуры, или не посылать в облако свои личные документы. А то и запускать бесчеловечные эксперименты над LLM так, чтобы superintelligence/skynet потом это не припомнил. Есть много моделей, оптимизированых для быстрой работы на устройствах с небольшой памятью. Но к сожалению, веса самых продвинутых моделей, которые играют в одной лиге с лучшими онлайн моделями, занимают сотни гигабайт. Например, 8-битные веса Deepseek R1-671B занимают 700 гигабайт, квантованые q4 — 350 гигов. Можно квантовать и в 1 бит, размер тогда будет около 90 гигов, но такая модель почти бесполезна. Еще есть много качественных finetunes на основе Mistral-Large-instruct-130B, Qwen2.5-72B, llama3.3-70B, веса которых также не помещаются в память старших моделей видеокарт.
https://habr.com/ru/articles/904172/